It was not so long ago, we discusses with my colleagues what is the best VARCHAR/NVARCHAR sizing since these string data types allocate space in pages based on char-count stored in dynamically.
I remember that there is a saying that you should size our VARCHAR/NVARCHAR columns with size you really need. But from first sentence of this post and MSDN definition it seems that it does not matter. These data types could adapt on string you put in. Let’s have look on its little bit closer. This could not be answered by an easy way.
Create two tables with columns, type of VARCHAR and different size for each table. In my sample I created one with VARCHAR(20) and another one with VARCHAR(1000). (Do not use VARCHAR(MAX) since it is another story, I will describe in one of my next POSTs).
CREATE TABLE _varchar_20( id VARCHAR(20)) CREATE TABLE _varchar_1000( id VARCHAR(1000) )
Fill the tables with data with text size corresponding to the table column with the lover VARCHAR size. In my case 20, it means that the second table column will be oversized.
INSERT INTO _varchar_20
SELECT REPLICATE('1',20)
FROM sys.objects a
JOIN sys.objects b ON 1=1
JOIN sys.objects c ON 1=1
INSERT INTO _varchar_1000
SELECT REPLICATE('1',20)
FROM sys.objects a
JOIN sys.objects b ON 1=1
JOIN sys.objects c ON 1=1
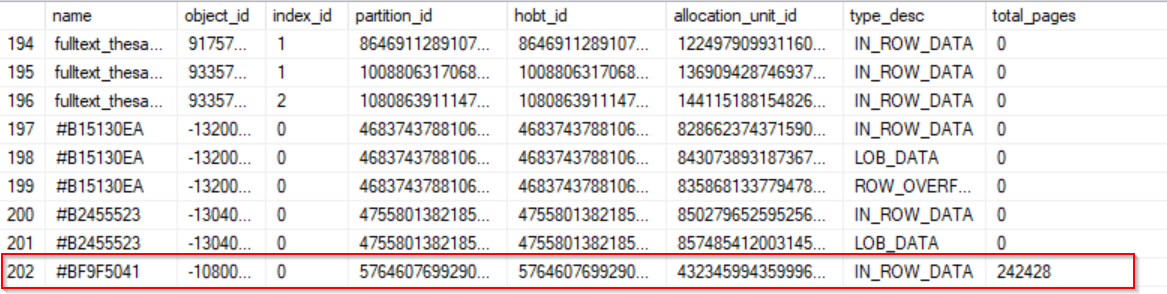
Let’s check how tables differs from the storage point of view.
SELECT so.name,
so.object_id, sp.index_id, sp.partition_id, sp.hobt_id, sa.allocation_unit_id, sa.type_desc, sa.total_pages FROM sys.objects so JOIN sys.partitions sp on so.object_id = sp.object_id JOIN sys.allocation_units sa on sa.container_id = sp.hobt_id WHERE so.name IN ('_varchar_20','_varchar_1000')
As we can see there is no different. Number of allocated pages is the same for all tables.

Now run simple select queries and compare execution plans to check if there is no impact on query execution.
SELECT * FROM _varchar_20 SELECT * FROM _varchar_1000
It seems that both execution plans are the same at first look.
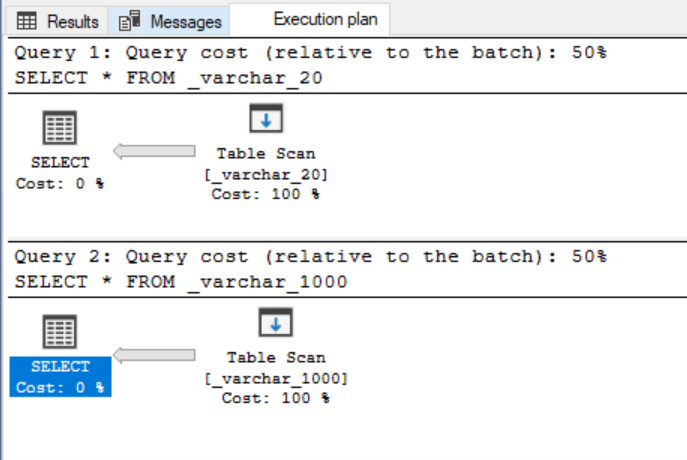
 The only one counter differs – Estimated row size but it has evidently no impact on query execution.
The only one counter differs – Estimated row size but it has evidently no impact on query execution.
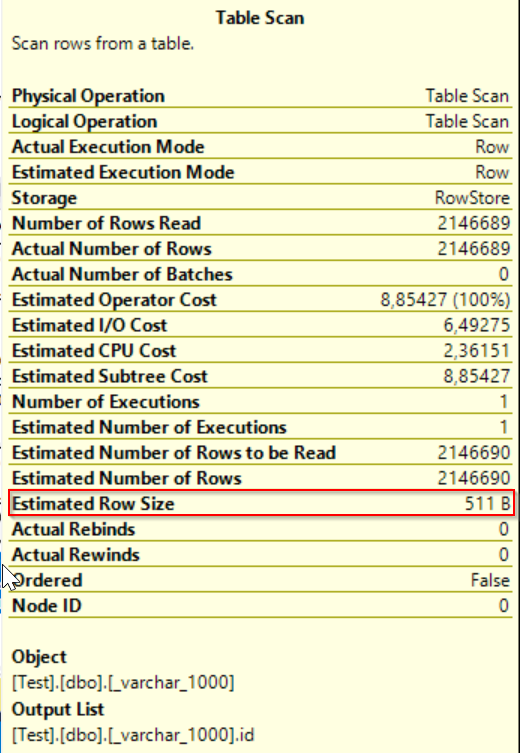
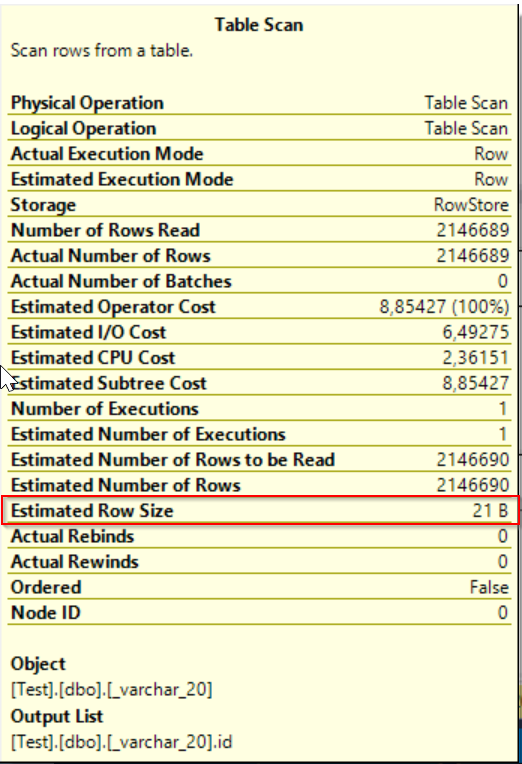
04 – Estimated Row Size

 Now we could say that sizing of VARCHAR/NVARCHAR has no impact on storage and query execution. BUT let’s modify our queries with sort operators and run them again.
Now we could say that sizing of VARCHAR/NVARCHAR has no impact on storage and query execution. BUT let’s modify our queries with sort operators and run them again.
SELECT * FROM _varchar_20 ORDER BY id SELECT * FROM _varchar_1000 ORDER BY id
As you can see query getting data from smaller column VARCHAR/NVARCHAR sizing run with less query costs and pefroms much better. What happened?
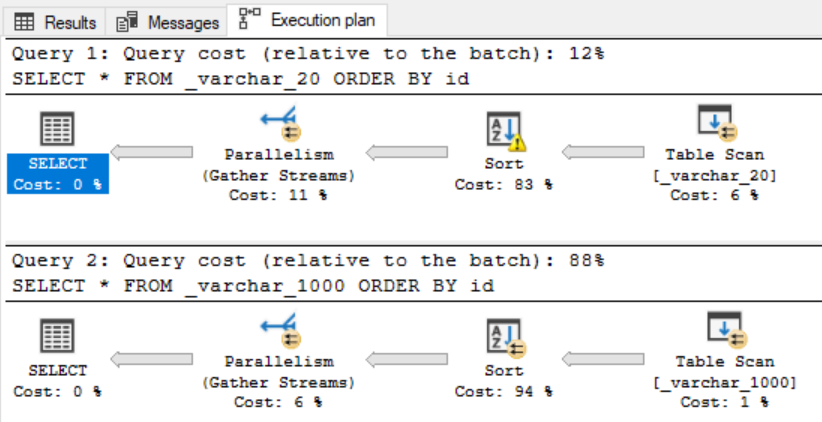

Click on SELECT operator to see its properties for both queries. As you can see there appeared row with MEMORY GRANT meaning that query asked for memory reservation based on Estimated row count as I mentioned above. Sometimes optimizer does not look at the data really stored in objects and checks statistics or catalog schema info, etc. as in this case.
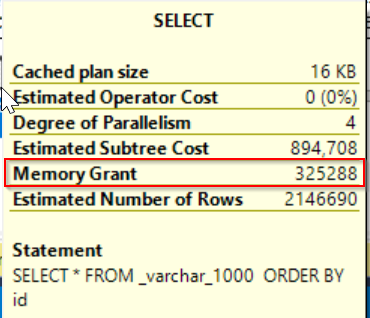
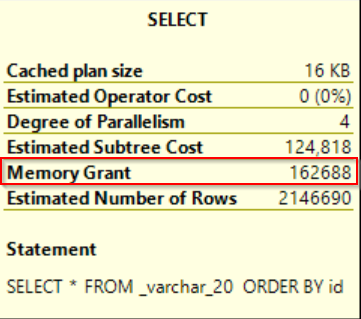
Picture 07 – memory grant

 So we could see that little change in query caused different query plans and costs estimation with better performance for smaller VARCHAR/NVARCHAR sizing.
So we could see that little change in query caused different query plans and costs estimation with better performance for smaller VARCHAR/NVARCHAR sizing.
My recommendation would states that it is better to size VARCHAR/NVARCHAR without oversizing columns when it is not really necessary. Of course there could be scenarios that you expect that data could increase in time. But to increase length of your VARCHAR/NVARCHAR column is still easier job that if you have to reduce it.
It would be interesting to take a look at this theme from more perspectives. I will continue with this topic in my next posts where I extend this theme to indexes, predicates, etc. Stay tuned!














 What is not still clear to me, or maybe I dont see it, why it is implemented this way. Table variable is defined like out of transaction scope table by Microsoft. Why there is a need to write data to transaction log, it seems useless to me.
What is not still clear to me, or maybe I dont see it, why it is implemented this way. Table variable is defined like out of transaction scope table by Microsoft. Why there is a need to write data to transaction log, it seems useless to me.