Multi-thread parallel inserts of multiple rows into one table without locks causing waits? I was convinced, that this task can be realized without deeper thinking about its implementation. But I am wrong, even though there are lots of posts on internet, describing that it is easy task.
I simulated this scenario on my laptop environment with SQL Server 2017 developer edition.
I have one table and I would like to insert data into the table from two sessions in parallel fashion. See structure of the heap table below.
CREATE TABLE dbo.ConcurentTable (b INT)
Execute long running insert to the table which should cause wait of another insert running in next query window.
BEGIN TRAN INSERT INTO dbo.ConcurentTable SELECT TOP 20000000 a.object_id FROM sys.objects a WITH (NOLOCK) JOIN sys.objects b WITH (NOLOCK) ON 1=1 JOIN sys.objects c WITH (NOLOCK) ON c.object_id=a.object_id COMMIT
Here we have the short one insert.
BEGIN TRAN INSERT INTO dbo.ConcurentTable (b ) SELECT TOP 100000 a.object_id FROM sys.objects a WITH (NOLOCK) JOIN sys.objects b WITH (NOLOCK) ON b.object_id=a.object_id COMMIT
Now run the long running query in first query window and then the query in the second one window.
In my environment I see that the second one query is waiting till the first one is finished.
What is the reason? Let’s look on the lock type first. Use dynamic views or sp_lock proc to get following output.
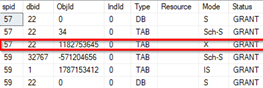
You can see that there is an exclusive lock as expected according to documentation defining that DML operations use exclusive locks to protect more processes trying to change the same data. Used for data-modification operations, such as INSERT, UPDATE, or DELETE. Ensures that multiple updates cannot be made to the same resource at the same time. Seehttps://bit.ly/39trAiq
The lock escalated to Table Resource level, because it is default behaviour of SQL server. The table level is more convenient for SQL server in our scenario because it spares some more resources. If SQL server would use lower level of locking mechanism, for example row resource level, for such a huge amount of inserted data, there will be lots of locks on lower level which is very time and resource consuming with impact on transaction log, etc…
I played with count of inserted rows to get locks on lower resources. When I get smaller batch for insert (about 2000 on my environment), SQL Server used Lock escalation on row level. For smaller amount of data, SQL Server would prefer to use lower resources to lock. Now you could see RID lock (because we don’t have any index on the table) which means that the whole table is not locked exclusively but its ranges of rows only.
Notice: There is defined threshold when SQL Server decides to use lock escalation. I found information in SQL Server 2008 Internals book.
-
The number of locks held by a single statement on one object, or on one partition of one object, exceeds a threshold. Currently that threshold is 5,000 locks, but it might change in future service packs. The lock escalation does not occur if the locks are spread over multiple objects in the same statement—for example, 3,000 locks in one index and 3,000 in another.
-
Memory taken by lock resources exceeds 40 percent of the non-AWE (32-bit) or regular (64-bit) enabled memory and the locks configuration option is set to 0. (In this case, the lock memory is allocated dynamically as needed, so the 40 percent value is not a constant.) If the locks option is set to a nonzero value, memory reserved for locks is statically allocated when SQL Server starts. Escalation occurs when SQL Server is using more than 40 percent of the reserved lock memory for lock resources.
But as I understood from other blog posts and discussions, above mentioned could change from distribution to distribution. It would be better to make some tests find the threshold on your environment. I am going to write another post about this topic.
Is there a way to manage above mentioned for huge batches of inserted data?
Let’s try.
We can use hint to force query to use lower resource level – ROW or PAGE. We can use ROWLOCK hint to force lock escalation on low resource level. But as states in documentation SQL Server still can decide which locking level will be used.
INSERT INTO dbo.ConcurentTable WITH (ROWLOCK)
To prevent such a behaviour, we can disable lock escalation on our table. Run following command. (there are other ways to change the lock escalation behaviour even on SQL Server level, but let’s describe in another post).
ALTER TABLE dbo.ConcurentTable SET (LOCK_ESCALATION = DISABLE)
Run the queries to simulate our scenario again. From sp_lock output you can see now exclusive lock on RID resource since we have heap table.
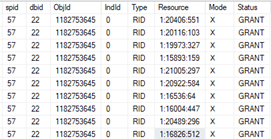
RID locks Now you should be successful with your second one query. The data were inserted before the first one query is finished, without waiting. In my environment I have occasionally problems with RID lock and PAGE lock. Seems to me that these two kinds of locks cannot guarantee concurrent batch inserts in the same time. I extend the table about additional attribute to split the inserted data and support concurrent inserts with KEY lock, see below.
Notice you can check waiting behaviour with NOWAIT hint which raises error in case the query is waiting.
Msg 1222, Level 16, State 45, Line 13
Lock request time out period exceeded.
Let’s add an attribute to distinguish batches of data based on SPID and sort he tables according to it.
ALTER TABLE dbo.ConcurentTable ADD spidFilter SMALLINT NOT NULL DEFAULT @@spid ALTER TABLE dbo.ConcurentTable ADD CONSTRAINT chSPidFIlter CHECK (SPIDFILTER = @@SPID) CREATE CLUSTERED INDEX CX_ConcurentTable ON dbo.ConcurentTable (SPIDFILTER )
Here we got it.
The second one query finished while the first “blocking” one is still running. In sp_lock we can see that there is KEY lock resource type used because of added clustered index.
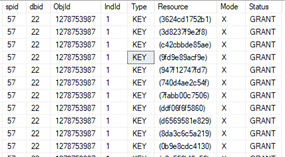
KEY locks When I tried to put lock escalation back on the table, I returned at the beginning – table lock and the second query was waiting till the first one was finsihed.
Closure
I was successful in concurrency scenario when 2 batches were inserted data to the same table from multiple threads with:
- Lock escalation on the table was disabled
- Query was forced to use lock on low resources level
- Clustered index design to separate inserted rows helped with count of succesfull experiments
- Locks on lower level resources hepled to increase concurrency of inserts in general
Notices
- Still not sure if above mentioned will work in all cases
- This forced lower level escalation approach does not block the second query but from point of view of resources it could be better strategy to leave the first one query finish and after that to execute the second one query ( the behaviour we tried at the beginning of this post). But this could be subject of other tests and play I will realize in one of my next post
- If you know any better way how to manage above mentioned scenario, please share it
Stay tuned

















